[DB] 벡터 DB: Milvus 사용 후기
프로젝트를 하는 중 shape matching 과정 중에 벡터 검색이 필요한데, 이를 빠르게 해야 할 필요가 있었다.
그 중 고민이 되었던 것이 벡터 DB의 선정 과정이었다.
따라서 PostgreSQL의 pgvector 익스텐션과 Milvus의 사용 둘 중 하나를 고민했다(사실 엄밀히 말하면 그 정도의 대규모 데이터는 필요하지 않지만 나름대로 고려해보았다)
1. 충분한 래퍼런스를 찾을 수 있는가?
- Milvus는 커뮤니티가 크다.
- pgvector 또한 커뮤니티가 크다(한국어 자료가 많다).
pgvector > Milvus (1 : 0)
2. 확장 가능성
- Milvus는 클러스터 단위로 확장이 가능하고, Query 노드와 Index 노드, 데이터 노드 등을 따로 확장시킬 수 있다.
- pgvector는 확장 가능성은 부족하다.
pgvector < Milvus (1 : 1)
3. 성능 차이
- 아래 글을 보면 Milvus의 성능이 종합적으로 좋다는 것을 알 수 있다(CPU, GPU, 서로 다른 하드웨어 아키텍처 환경도 다 지원하기까지 하다)
- 열 기반 DB이기에 검색이 더욱 빠르다.
2023년, 벡터 데이터베이스 선택을 위한 비교 및 가이드 / Picking a vector database: a comparison and guide for
벡터 데이터베이스 선택을 위한 비교 및 가이드(2023년) / Picking a vector database: a comparison and guide for 2023 작성자(Author): 에밀 프뢰베르크 / Emil Fröberg, Vectorview 공동 창업자 개요 / Introduction 시맨틱 검
discuss.pytorch.kr
pgvector < Milvus (1 : 2)
4. 결국 내가 빠르게 개발할 수 있는가? (이게 가장 중요하다)
- Milvus는 예시 코드를 보니 그렇게 어려워보이지 않았다.
- pgvector는 ORM 등을 사용하여 개발하면 전통적인 DB를 사용하는 것과 차이가 없다.
pgvector > Milvus (3 : 2) (가장 중요하니 가중치 2)
그렇기에 실리적으로는 pgvector를 선택하는 것이 맞다(회사였다면 프로토타입이니 무조건 pgvector를 사용했을 것이다).
하지만 막연하게 이전부터 벡터 DB를 사용하고 싶었기에 이번 프로젝트에서는 Milvus를 사용하였다(이 결정을 가끔씩 후회하기도 했다).
프로토타입 제작 이후 Milvus 개발 경험 회고
기준: 50차원의 데이터셋 20개, bulk vector search 400개 기준
1. 성능은 만족스럽다
- 아무리 데이터셋이 20개 정도지만 bulk vector search인데 200ms 이내였다.
2. 개발 경험은 최악에 가까웠다
- milvus-standalone 기준 wsl2 환경에서 메모리를 8GB 정도를 할당해주지 않으면 자주 wsl이 shutdown된다(8GB도 가끔 shutdown된다).
- 객체 스토리지인 MinIO가 가끔 맛이 가서 SDK로는 안되고 GUI는 접속이 되는 경우가 꽤나 자주 발생한다.
- SDK가 있는데, Python의 경우에는 SQLAlchemy과 같이 자연스러운 ORM이라고 하기에는 어려웠다(비교적 최근에 도입된 MilvusClient로 개발하는 경험도 래퍼런스가 적어 아쉬웠다. 특히 커넥션 풀이 자체 제공되지 않는다!)
- GUI로 Attu가 있으니 docker compose로 사용을 추천한다.
따라서 빠르고 편한 개발 경험이 우선이라면 pgvector 사용을 추천한다.
Milvus 시작하기
Milvus 타입
Milvus는 3가지 타입이 존재한다.
Milvus Lite:
- 빠른 프로토타입용으로 추천한다
- jupyter notebook에서도 사용이 가능하다
- edge device 용으로도 추천한다
Milvus Standalone
- 노드 하나에서 도커 환경 기반 배포 방식이다
- HA(High Availability)도 가능하다(master-slave replication이 가능하다)
- 메모리만 충분히 늘리면 1억개의 vector까지 감당이 가능하다고 한다
Milvus vector database documentation
Milvus v2.5.x documentation
milvus.io
세 가지 주요 component로 구성되어 있는데,
- minio: object storage로, S3와 호환된다
- etcd: Key-Value metadata 엔진으로 milvus의 내부 요소들에 접근 가능하다
- milvus: 핵심 기능 요소로, 아래와 같은 하위 컴포넌트로 나눠진다
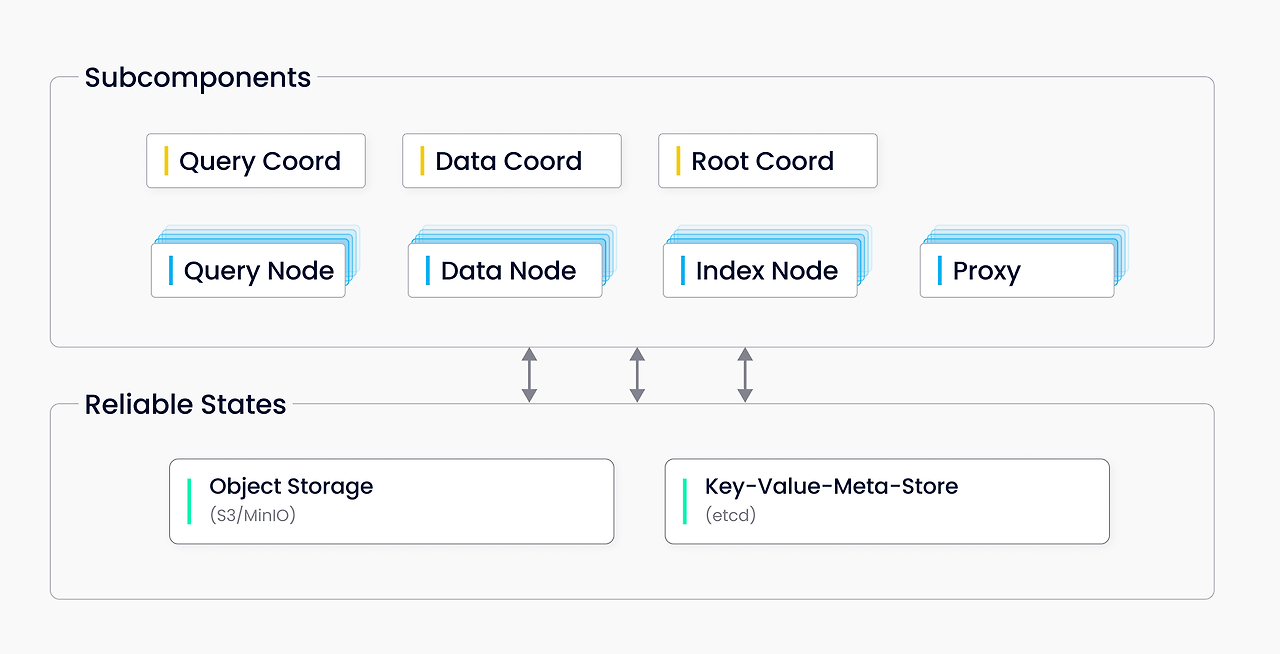
Milvus Cluster는 저 subcomponent들이 다 나눠진다고 볼 수 있다. 또한, 각각 독립적으로 스케일 업이 가능하다.
Milvus Distributed
- 쿠버네티스 클러스터 배포 방식이다
- CREATE 및 INSERT 기능, Search와 Query 등은 각각 다른 노드로 분리되어있고, 더 중요한 컴포넌트에 대해 확장이 가능하다
- Write Only와 Read Only를 나눠놓고, 스토리지는 공유하여 사용하는 방식이라고 볼 수 있다

위 모든 타입은 REST API를 지원한다.
Milvus Lite의 경우에는 gRPC도 지원하니 엣지 디바이스에서 더 좋을 것 같다.
Milvus 시작하기
기본 설정 및 클라이언트 연결
먼저 Milvus 클라이언트를 설정해야 한다.
from pymilvus import MilvusClient
client = MilvusClient(uri="http://localhost:19530", token="root:Milvus")
컬렉션
Milvus에서는 Collection이 테이블이며, 데이터를 저장하는 기본 단위이다.
Collection을 생성할 때 주의할 점은
- vector에 대한 dimension을 미리 설정해야 한다
- vector 컬럼이 없는 경우, Collection은 만들어지지 않는다.
- id는 auto-increment는 기본이 아니다.
- 기본 유사도 메트릭은 코사인 유사도이다.
텍스트 임베딩
텍스트를 벡터로 변환하기 위해서는 다음과 같이 설정하면 된다.
pip install "pymilvus[model]"
from pymilvus import model
embedding_function = model.DefaultEmbeddingFunction() # paraphrase-albert-small-v2 모델 사용
구체적으로는 아래를 참고하자
Milvus vector database documentation
Milvus v2.5.x documentation
milvus.io
데이터 관리
데이터 삽입
# dictionary 형태로 데이터 준비 (key가 column이 됨)
data = {
"text": ["sample text"],
"vector": [embedding_vector]
}
client.insert(collection_name="my_collection", data=data)
검색
results = client.search(
collection_name="my_collection",
data=[query_vector],
limit=5,
output_fields=["text"]
)
# 결과는 JSON 문자열로 반환되며, id와 distance는 항상 포함됨
추가로 'entity' 속성 하위에 output_fields에 기술한 field만 나온다.
필터링 검색
results = client.search(
collection_name="my_collection",
data=[query_vector],
filter="field_name == 'biology'"
)스칼라 값에 대한 인덱싱도 가능하기에 필터링에 사용하면 좋다.
쿼리 및 삭제 (업데이트는 없다)
# 쿼리
client.query(collection_name="my_collection", filter="field_name == 'value'")
# 삭제
client.delete(collection_name="my_collection", filter="field_name == 'value'")
벡터 인덱싱
기본적으로 검색 속도를 위하여 인메모리 인덱스를 사용하며, On-disk Index는 따로 존재한다
지원하는 인덱스는 아래와 같다.
Floating-point embeddings
기본 코사인 유사도와 유클리디안 유사도를 지원한다.
- FLAT: 전역 탐색
- IVF_FLAT: 클러스터 기반 검색
- IVF_SQ8: 8비트 양자화로 메모리 효율성 증가
- IVF_PQ: Product Quantization으로 차원 축소
- SCANN: 확장 가능한 최근접 이웃 검색
- HNSW: 계층적 그래프 기반 검색
Binary Embeddings
JACCARD, HAMMING 메트릭을 지원한다.
- BIN_FLAT
- BIN_INV_FLAT
Sparse embeddings
코사인 유사도만 지원한다.
- SPARSE_INVERTED_INDEX
- SPARSE_WAND (빠른 검색 속도, dense 데이터에서는 성능 저하)
추가로 참고하면 좋을 것들
효율적인 메모리 검색을 위한 BitSet
- filter set과 delete set을 OR 연산으로 묶어 0인 부분만 반환하며, timestamp 기반 검색도 filter set으로 진행 가능.
Milvus vector database documentation
Milvus v2.5.x documentation
milvus.io
벡터 연산 엔진 코어: Nowhere
- 기존 Faiss, Hnswlib, and Annoy 라이브러리. 여러 가지 인덱스에 대한 코드 베이스 존재.
Milvus vector database documentation
Milvus v2.5.x documentation
milvus.io
감사합니다.