안녕하세요.
이번 글은 아래와 같은 클라우드 아키텍처로 서비스를 배포하는 과정 중 생긴 일입니다.
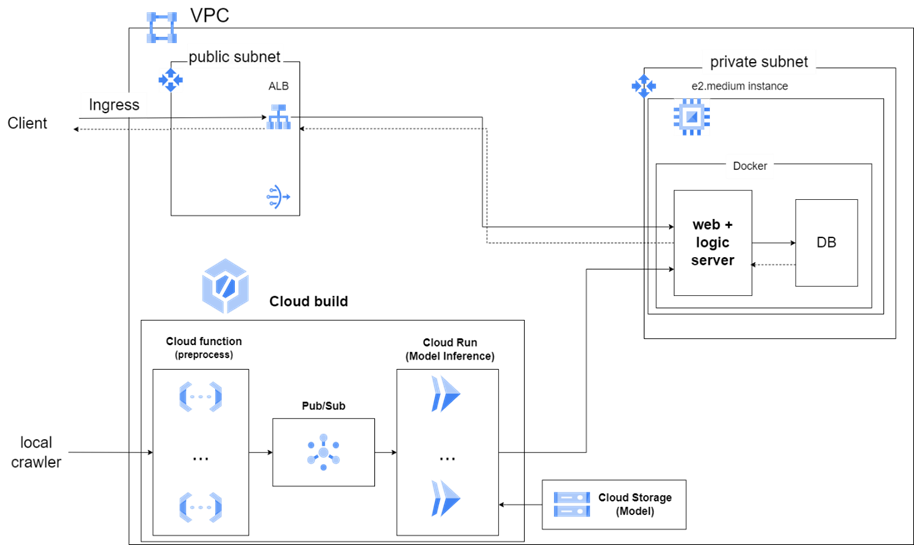
BERT 모델을 Cloud Run으로 배포한 이후, 추론한 결과를 Flask와 SQLAlchemy를 이용하여 BATCH UPSERT로 처리하는 중이었습니다.
그런데, CPU 사용량에 과부하가 와 서버가 터지고, DB에 데이터 삽입에 너무 오랜 시간이 걸렸습니다.
따라서 문제점을 여러 곳을 진단하다 아래와 같이 문제를 해결했습니다.
(문제점 진단은 이후에 제대로 포스팅을 하겠습니다)
1. 프로파일링
배웠던 @contextmanager 문법으로 cpu와 메모리 tracking을 로컬에서 진행하였습니다.
[Python] 클로저, 데코레이터, wraps, contextmanager
안녕하세요. 오늘은 클로저와 데코레이터에 대한 설명을 하고,파이썬 라이브러리에서 자주 쓰이는 데코레이터 중 하나인 wraps와 contextmanager에 대한 설명을 해보겠습니다. 클로저클로저는 겉
ket0825.tistory.com
코드는 아래와 같습니다.
from contextlib import contextmanager
import psutil
import time
@contextmanager
def track_usage_context(interval: float = 0.5):
start_time = time.time()
process = psutil.Process()
whole_cpu = psutil.cpu_percent(interval=interval, percpu=True)
print(f"Whole CPU: {whole_cpu}")
process_id = process.pid
process_name = process.name()
before_process_cpu = process.cpu_percent(interval=interval)
before_process_memory = int(process.memory_info().rss / 1024 / 1024 )# in MB
print(f"After Process ID: {process_id}, Process Name: {process_name}, CPU: {before_process_cpu}, Memory: {before_process_memory}MB")
try:
yield
finally:
end_time = time.time()
after_process_cpu = process.cpu_percent(interval=interval)
after_process_memory = int(process.memory_info().rss / 1024 / 1024) # in MB
whole_cpu = psutil.cpu_percent(interval=interval, percpu=True)
print(f"Whole CPU: {whole_cpu}")
print(f"After Process ID: {process_id}, Process Name: {process_name}, CPU: {after_process_cpu}, Memory: {after_process_memory}MB")
print(f"Execution time: {end_time - start_time}")
print(f"Difference in CPU: {after_process_cpu - before_process_cpu}, Difference in Memory: {after_process_memory - before_process_memory}MB")
사용법
with track_usage_context(interval=0.5):
select_stmt = select(Review.n_review_id, Review.reid) \
.where(
Review.n_review_id.in_(
[review.get('n_review_id') for review in reviews]
)
)
exists = db_session.execute(select_stmt).all()
이렇게 DB에 쿼리를 실행하는 코드 블럭마다 트래킹을 진행하였는데 위와 같은 로직에서 시간 소요가 크다는 것을 확인하였습니다.
2. EXPLAIN을 활용한 쿼리 최적화
아래와 같이 쿼리 분석을 실시하였습니다.
from sqlalchemy import text
def explain_query(query):
query = query.compile(engine, compile_kwargs={"literal_binds": True})
explain_stmt = text(f"EXPLAIN {query}")
res = db_session.execute(explain_stmt).fetchall()
for row in res:
print(row)
explain_query(select_stmt)
결과는 아래와 같았습니다.
(1, 'SIMPLE', 'review', None, 'ALL', None, None, None, None, 284107, 50.0, 'Using where')
단순 Where 조건을 사용하였고, 탐색 예상 레코드 수는 28만 개에 달하였습니다.
(해석 참고)
[MySQL] 실행계획 (explain) 보는법
◈MySQL 실행계획 Example id: 1 select_type: PRIMARY table: t1 type: index possible_keys: NULL key: PRIMARY key_len: 4 ref: NULL rows: 4 filtered: 100.00 Extra: Using index id 쿼리 내의 select 문의 순서 select_typeselect문의 유형 SIMPLE:
gradle.tistory.com
결론적으로 n_review_id 컬럼을 IN으로 범위 SELECT를 하는데 인덱스를 사용하지 않아서 매우 속도가 느린 것이었습니다.
MySQL Workbench로도 확인하였더니 인덱스가 설정되있지 않더군요(분명 TABLE 만들 때 설정했었는데...).
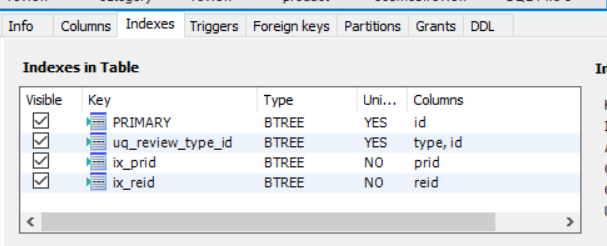
그래서 다음과 같이 인덱스를 생성하였습니다.
ALTER TABLE COSMOS.REVIEW ADD INDEX ix_n_review_id (n_review_id);
변경 후 쿼리를 EXPLAIN한 결과가 아래와 같이 새롭게 나왔습니다.
(1, 'SIMPLE', 'review', None, 'range', 'ix_n_review_id', 'ix_n_review_id', '402', None, 5, 100.0, 'Using index condition')
5개의 레코드만 확인한다고 예상하고 있고, 인덱싱이 잘 걸려있다는 것을 확인하실 수 있습니다.
이후 요청을 Postman으로 비교하였습니다.
변경 전 request 시간.

변경 후 request 시간.

결론: 설정한 인덱스도 다시보자
'Data Engineering > DB' 카테고리의 다른 글
| [DB] 벡터 DB: Milvus 사용 후기 (1) | 2025.01.10 |
|---|
